
One of the accomplishments at IRG #42 last month was the addition of 29 new CJK Unified Ideographs to the URO (Unified Repertoire & Ordering), specifically from U+9FCD through U+9FE9. The first four are shown above.
The first three characters, U+9FCD through U+9FCF, were the result of a UNC (Urgently Needed Character) submission from China (IRG N1967) that included three characters from 通用规范汉字表 (Tōngyòng Guīfàn Hànzìbiǎo). Speaking of that standard from China, I created a revised mapping table that includes these three mappings.
The next character, U+9FD0, was the result of disunifying U+4CA4 (䲤). The simplified form remains at U+4CA4, and the traditional form whose source is Hong Kong SCS-2008 will be encoded at U+9FD0. For compatibility reasons, it makes sense for fonts that support Hong Kong SCS to map both U+4CA4 and U+9FD0 to the same glyph, at least for a small number of years.
The next five characters, U+9FD1 through U+9FD5, were the result of the UTC’s revised UNC submission (IRG N2005).
The last 20 characters, U+9FD6 through U+9FE9, were the result of a UNC submission from UC Berkeley’s Script Encoding Initiative (IRG N1954).
For those who would like to glance at the complete Code Chart excerpt, it is shown below in delta-style (new characters are highlighted in yellow):
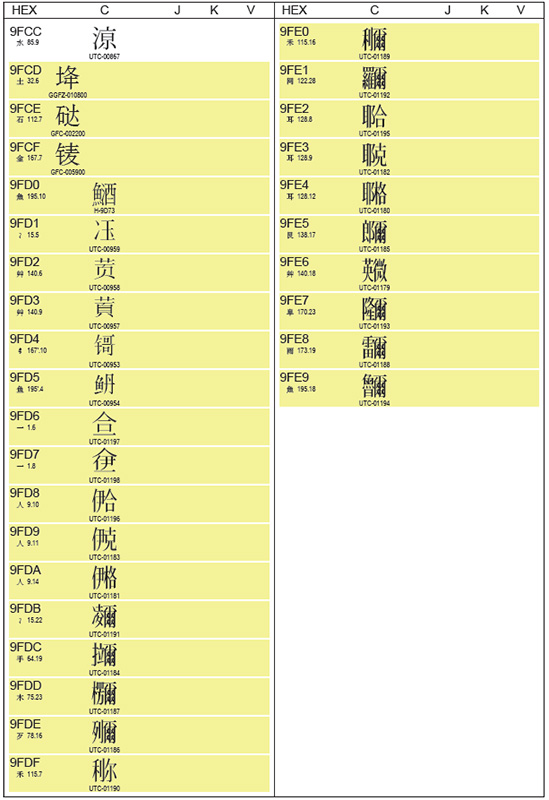
Anyway, the next steps are these to be approved by WG2 and the UTC, but because there’s nothing particularly controversial about them, they should be encoded as soon as the pipeline allows.
Back to the grind…