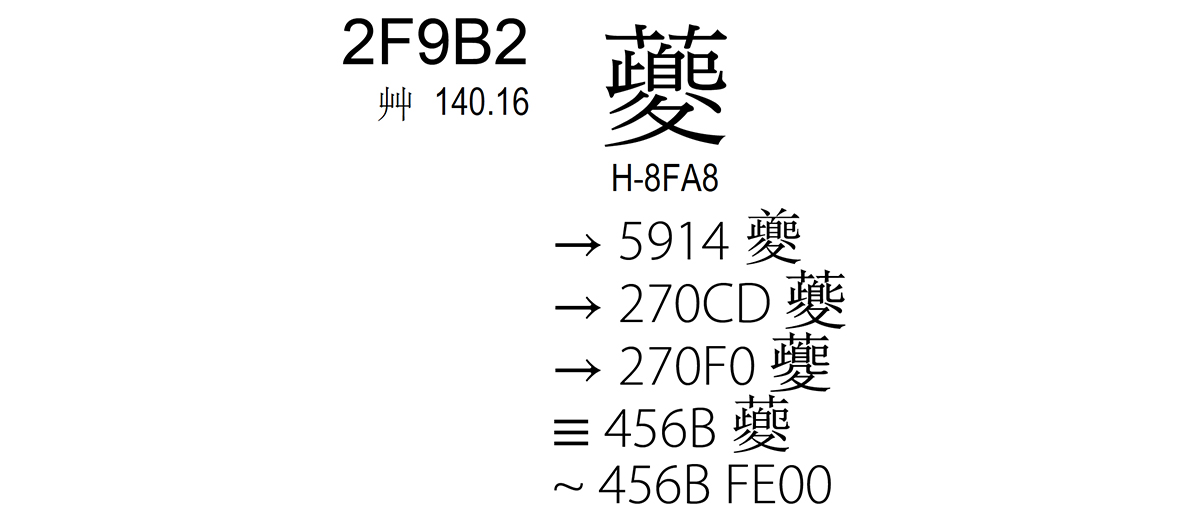
U+2F9B2 䕫 is a CJK Compatibility Ideograph, and like all CJK Compatibility Ideographs, it canonically decomposes to a CJK Unified Ideograph, and also has a Standardized Variation Sequence (SVS) that uses its canonical equivalent as its base character. This character also has a single source reference, H-8FA8, which corresponds to HKSCS (Hong Kong Supplementary Character Set) 0x8FA8.
So, what’s the problem? Put simply, its canonical equivalent, U+456B 䕫, is neither in HKSCS nor in its Big Five subset:

If this character is ever normalized—regardless of the normalization form—it is converted to its canonical equivalent, U+456B 䕫, which is not likely to be included in fonts that are designed for use in Hong Kong SAR. Furthermore, even if its SVS, <U+456B,U+FE00>, is used, there is a similar problem in that its base character is also not likely to be present in fonts that are designed for use in Hong Kong SAR.
As shown in the metadata for U+2F9B2 䕫 above, there are other related CJK Unified Ideographs, two of which happen to have H-Source source references: U+5914 夔 and U+270CD 𧃍. Their code chart excerpts are shown below:


U+5914 夔 is included in the Big Five subset, and U+270CD 𧃍 is in HKSCS proper.
Anyway, I can think of three possible solutions for this problem:
- Add U+456B 䕫 to the HKSCS standard and submit a horizontal extension to add HD-345B as a new H-Source source reference for U+456B 䕫.
- Change the mapping for HKSCS 0x8FA8, H-8FA8, from U+2F9B2 䕫 to U+456B 䕫.
- Change the mapping for HKSCS 0x8FA8, H-8FA8, from U+2F9B2 䕫 to U+270F0 𧃰.
The second and third solutions would effectively orphan U+2F9B2 䕫, which means that a new U-Source reference that uses the “UCI” prefix would need to be assigned and added to UAX #45 (U-Source Ideographs). Speaking of the third solution, this is what U+270F0 𧃰 looks like:

My pick would be the second solution, mainly because U+456B 䕫 is not currently included in HKSCS, and it reduces the number of CJK Compatibility Ideographs that HKSCS needs, which is a Very Good Thing™. Besides, U+2F9B2 䕫 canonically decomposes to U+456B 䕫, which means that they are unifiable, and any use of U+2F9B2 䕫 that is normalized will become U+456B 䕫 anyway. The best alternate solution would be the first one, which simply involves adding U+456B 䕫 to HKSCS, but this means that the representative glyphs for the two characters would be the same, with U+456B 䕫 being the preferred one because it is a CJK Unified Ideograph.
Lastly, changing the canonical equivalent for U+2F9B2 䕫, from U+456B 䕫 to U+5914 夔, is a complete non-starter due to stability policies, as is encoding a new CJK Compatibility Ideograph due to normalization concerns.
Any thoughts from the readership? If so, please make the effort to post a comment.
2017-10-14 Update: According to IRG N2268, which is dated yesterday and which will be discussed during IRG #49 next week, Hong Kong SAR decided to resolve this issue through Solution #3 mentioned above, which entails remapping HKSCS 0x8FA8, H-8FA8, to U+270F0 𧃰.