
(翻訳:Adobe Type チーム 山本太郎、西村美苗)
(この記事中の事項はすべて、Google の Pan-CJK 書体ファミリー、Noto Sans CJK にもあてはまる。源ノ明朝に言及している場合には Google の Noto Serif CJK にもあてはまる。)
源ノ角ゴシックファミリーを、Google により製品化されたバージョンである Noto Sans CJK ファミリーも含めて、バージョン 1.004 にアップデートしたのは、2015 年 6 月だった。以来、さまざまな計画を立案し、また膨大な量の準備と作業を積み重ねてきた。その結果、Pan-CJK フォントファミリー:源ノ角ゴシックと Noto Sans CJK のバージョン 2.000 が誕生した。
バージョン 2.000 での変更・改良点の詳細について関心があれば、以下を参照されたい。
CJK 統合漢字拡張 G
近日中に符号化される予定の CJK 統合漢字拡張 G に含まれる二つの漢字の字形が五つの言語(日本語、韓国語、中国語簡体、台湾の中国語繁体、香港の中国語繁体) によってどのように異なっているかを、本記事冒頭のアニメーションで分かりやすく示している。各ウェイトは七色の虹色の内の一色で示されている。それぞれの漢字には 4 個のグリフが必要で、それらが五つの言語によってどのように使い分けられているかは両者で異なっている。これらの二文字とは別に、更に二つの漢字も拡張 G には含まれている。その二つが必要とするグリフも、本フォントに含まれている。
現時点では拡張 G のコードポイントはまだ確定していないため、これらのグリフは IDS(Ideographic Description Sequence)を介して入力する必要があり、IDS は入力されると、OpenType ccmp(Glyph Composition/Decomposition)GSUB フィーチャで処理される。詳細は ReadMe ファイルの「CJK Unified Ideographs Extension G」(CJK 統合漢字拡張 G)の章と 13 ページにある表を参照されたい。
拡張 G に含まれる四文字の漢字は、アドビのフォントデザインチームのメンバーにより作成された。その内二文字は、繁体と簡体の「びゃん」で、この二文字のためのグリフはかつてのメンバーである吉富ゆいが手がけた。後に、吉田大成が微調整を施し、またそれぞれの地域用に必要なグリフもデザインした。記事冒頭のアニメーションの左に示しているのが、繁体のグリフだ。吉田は拡張 G の他の二文字用のグリフもデザインした。その内の一つは、アニメーションの右側に示す 84 画もある「たいと」だ。これらのグリフはどれも Pan-CJK フォントの書体デザインプロジェクト全般を監督しているチーフデザイナー西塚涼子により、もちろんチェックされている。
香港への対応
バージョン 2.000 のアップデートでもっとも時間を要したのは、中国語繁体に第二のグループを追加したことだった。香港の文字セット標準 HKSCS-2016 に対応するためのもので、結果的としてフォントの数は 16 個増え、72 個から 88 個となった。Super OTC フォントは、私が一番好むフォントファイル構成だが、それに含まれるフォント数は 36 から 45 に増えた。
約 1,400 個の HK(香港用)グリフを新たにデザインし、750 以上の既存の HK グリフを修正するという膨大なデザイン作業に取り組んだのはアドビのパートナー Arphic Technology(文鼎科技)のデザインチームだ。このチームがさらに 50 の新しい CN(中国)用グリフ、約 150 の新しい TW(台湾)用グリフもデザインし、約 125 の CN(中国)用グリフと約 400 の TW(台湾)用グリフの修正も行った。
Web ブラウザーが香港用の言語タグに対応するようになってから、かなりの年月が経っている。そこで、ブラウザーでは香港に対応したフォントが正しく動作することはオープンソースのテスト用フォントである LOCL Test(LOCL テスト)を使って確認することができた。Adobe のアプリケーションでは香港用言語タグへの対応がなされたのは、十月に開催された Adobe MAX(米国)にあわせてリリースされた Adobe InDesign CC 2019 が最初である。
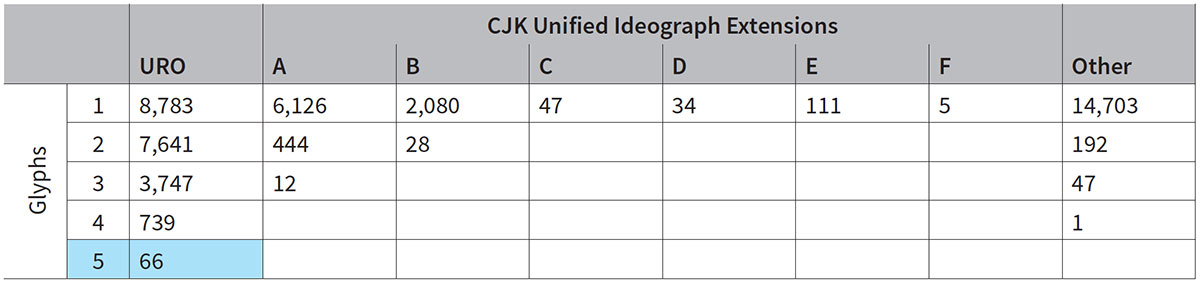
五番目となる言語の対応を追加する上でのチャレンジの一つは、すべての言語が異なるグリフを必要としている文字があることだった。すべての文字とグリフのマッピングを分析した結果、5 個のグリフを必要とする文字は 66 個あることがわかった。また、4 個の異なるグリフを必要とする文字の数はバージョン 1.004 では 314 文字だったが、バージョン 2.000 では 739 文字に増えた。これは HK(香港)用のグリフが大きく増えたためだ。
ボポモフォ対応の改善
ごく少数ではあるが、新規に(または近々)符号化されるボポモフォ(中国語用注音符号)を追加し、さらにこの機会にグリフ形状を大幅に改良し、声調記号も追加して利用しやすくした。チーフデザイナー西塚涼子は、ボポモフォが未知の分野であったにもかかわらず、事実上ほとんどのボポモフォグリフをデザインし直すというチャレンジに取り組んだ。当然のことながら、西塚は専門家からの貴重なフィードバックを得ながら、そのデザイン作業を進めた。下に示すアニメーションでは、バージョン 2.000 のグリフを黒で、バージョン 1.004 のグリフを青で重ねている。

ボポモフォと声調記号への対応を無理なく行うために、主として GDEF(Glyph Definition)テーブル、mark(Mark Positioning)GPOS フィーチャ、ruby(Ruby Notation Forms)GSUB フィーチャを追加した。さらに GSUB と GPOS フィーチャである vert(Vertical Alternates)に関連する作業も行った。
源ノ明朝との整合
2017 年前半にリリースされた源ノ明朝には、源の角ゴシック 1.004 に比べていくつかの改良がなされており、同様の改良を源の角ゴシック 2.000 でも行った。
- CIDFont と CMap のリソースに XUID の配列を含めない。この記事にあるように、それはもはや不要だからだ。
- U+0000 から U+001F までのコード範囲にはグリフを割り当てない。これも不要と考えられるからだ。
- 「Halfwidth Jamo variants」(半角のハングル字母の異体字)に対応するコードポイントは、「Hangul Compatibility Jamo」(ハングル互換字母)ブロック中のコードポイントに対応するグリフに対応づけた。これによって、半角の字母のグリフは削除された。
- name(Naming)テーブルは Macintosh(PlatformID=1)の文字列を含まない。これによって name テーブルがより簡潔になった。
- Regular ウエイトは Bold ウェイトに対応づけられている。これにより、テキストを太くするためのスタイルリンキングに対応しているアプリケーションのフォントメニューでは、Bold ウェイトが現れない可能性がある。
- vert GPOS フィーチャが含まれる。このことは、vert の GPOS フィーチャに対応するアプリケーションでは、合成のハングル字母が縦組みでも動作することを意味する。このフィーチャにより、縦組みで正しく動作するグリフは他にもいくつかある。
- 非推奨の hngl(Hangul)GSUB フィーチャを、デフォルト言語が韓国語のフォントから削除した。
文字とグリフのマッピングの追加
155 の文字とグリフのマッピングを CMap リソースに追加し、これらの文字が利用しやすくなった。
バージョン 1.004 のフォントは 44,651 のマッピングを含んでいたが、バージョン 2.000 のフォントは 44,806 のマッピングを含む。新規のマッピングの内、66 個は BMP(基本多言語面)のコードポイントから、22 個は面 01 のコードポイントから、残りの 67 個は面 02 からのコードポイントだ。新規の 67 個の面 02 のコードポイントの内、57 個は CJK 統合漢字拡張 B から、2 個は拡張 C から、3 個は拡張 E から、残りの 5 個は拡張 F からのものだ。
次に示す表は、ReadMe ファイルの 15 ページにある「Glyph Sharing Statistics」(グリフの共有に関する統計)からの抜粋で、バージョン 2.000 の 44,806 のマッピングがどのように分布し、グリフが五つの対応言語間でどの程度共有されているかを示す:
次に示すアニメーションは五つの地域がそれぞれ異なったグリフを持つ 66 の漢字を示している:

CJK 統合漢字拡張 G が安定する頃には、面 03 のコードポイントからの 4 個のマッピングも追加されるだろう。
他の改良点
上記以外にも、下記のような改善がなされた。同様の改善を近い将来、源ノ明朝のバージョンを 2.000 にアップデートする際にも適用する予定だ。
- locl(Localized Forms)と vert GSUB フィーチャにおける言語と用字系の宣言名を改良した。
- URO(Unified Repertoire & Ordering)は U+9FEF(Unicode バージョン 11.0)までのすべてを含んで完結している。
- TW(台湾)用および HK(香港)用の数百のグリフで用いられる 162 番の部首、辶(U+2ECE/U+8FB6)の形状を改良した。次に示す画像は、バージョン 1.004(左)とバージョン 2.000(右)を示している:
- いくつかの仮名文字のグリフに修正を加えた。
- コードポイント U+32FF に対応するグリフとして仮の空白グリフ uni32FF と uni32FF-V を含む。これは日本で改元が行われる 2019 年 5 月 1 日の時点で想定されているフォントの改訂を容易に行えるようにするためだ。改訂版ではこれらの空白グリフは新元号用の横書き用と縦書き用の合字(二つの漢字から成るグリフ)に置き換えられる。
- ReadMe ファイルに対して種々の改良・拡張を加えた。

終わりに:多大の努力により、私たちはバージョン 2.000 へのアップデートを実現した。ぜひご利用いただきたい。何にもまして心が弾むのは、香港用に中国語繁体字の第二のバリエーションを提供できたことだ。その設計と実装には少なからぬ時間と努力を要した。
追伸:次の仕事として、Adobe Clean Han(Adobe Clean 角ゴシック)ファミリーのアップデートがある。それによって、本ブログの表示に使われている Adobe Clean Han も、バージョン 2.000 になるわけだ。
Unicode U+1B001〜U+1B11Eで規定されてる286文字の変体仮名についても、対応してほしい。
Adobe-Japan1だけでなく、Hanyo-Denshiの異体字セレクタにも対応してほしい。
Supporting the Hanyo-Denshi IVD Collection is a non-starter for a variety of reasons. First and foremost, other than the glyph charts for that collection, there is no longer a stable web page that describes the collection, which is one of the requirements. As the IVD Registrar, I have repeatedly asked Japan to restore its URL so that the one that is reflected in the IVD_Collections.txt file is no longer stale. Secondly, I consider that IVD collection to be deprecated in favor of newer Moji_Joho IVD Collection, and supporting that IVD collection is well beyond the scope of the Source Han projects. With that said, this is an open source project, so you’re more than welcome to do this yourself for your own purposes.