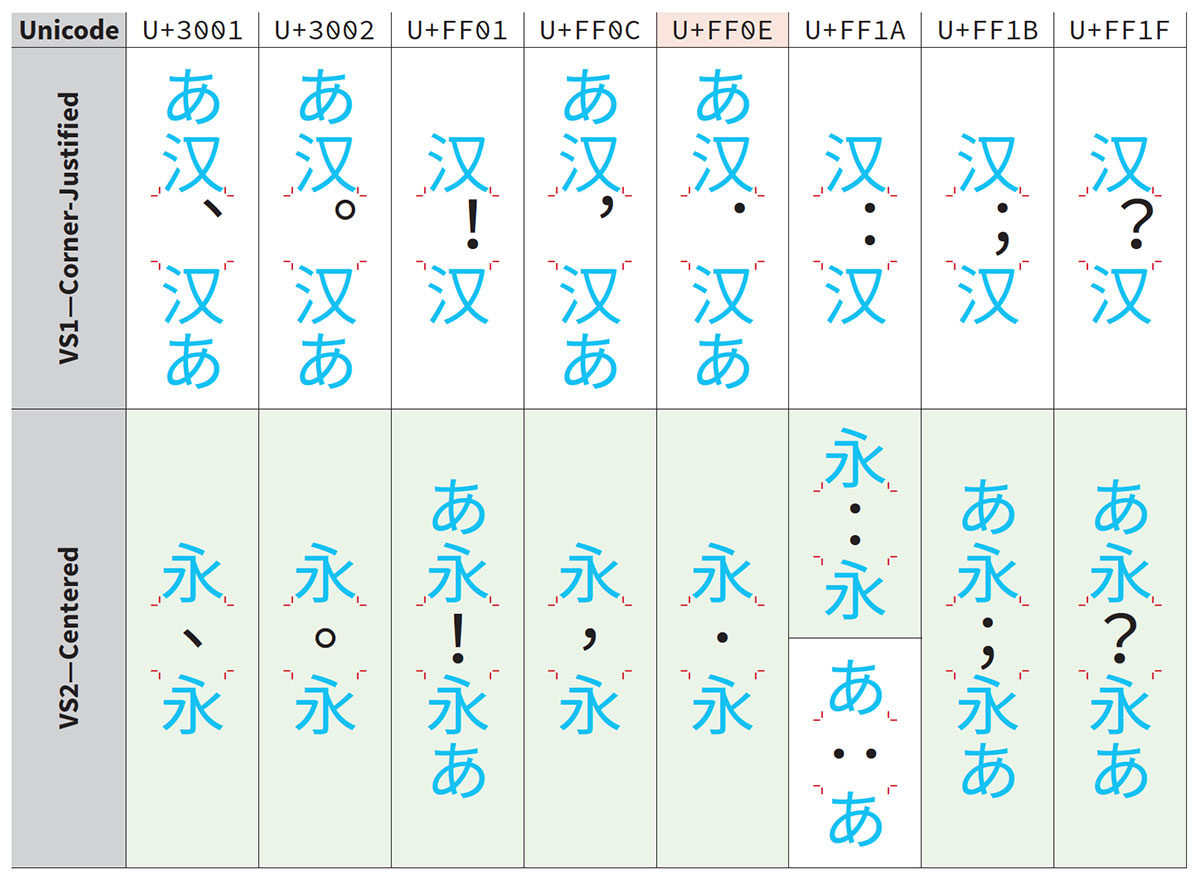
This is a brief article to report that the 16 SVSes (Standardized Variation Sequences) for eight full-width punctuation characters—U+3001 、 IDEOGRAPHIC COMMA, U+3002 。 IDEOGRAPHIC FULL STOP, U+FF01 ! FULLWIDTH EXCLAMATION MARK, U+FF0C , FULLWIDTH COMMA, U+FF0C , FULLWIDTH COMMA, U+FF1A : FULLWIDTH COLON, U+FF1B ; FULLWIDTH SEMICOLON & U+FF1F ? FULLWIDTH QUESTION MARK—that I proposed in L2/17-436 were accepted for Unicode Version 12.0 during UTC #154 this week. After reading the Script Ad Hoc group’s comments, I prepared a revised version (L2/17-436R) that provided additional information as a response to the two comments, which included the table that is shown above, and this served as the basis for the discussions.
This all began with a proposal that I submitted four years ago, L2/14-006, which was resurrected as L2/17-056, and finally discussed during UTC #153 during which I received constructive feedback. This prompted me to split the proposal into two parts. The first part proposed the less-controversial SVSes, which are the ones that were accepted. The second part, L2/18-013, proposes the more controversial ones. I am fully expecting to revise the second part before it is discussed during UTC #155, which begins on 2018-04-30.
I would like to use this opportunity to solicit comments and feedback for L2/18-013, which would be taken into account when I revise it. (I also hope to receive feedback from the Script Ad Hoc group prior to UTC #155, which would also be taken into account.)
In closing, the 16 new SVSes should soon appear in The Pipeline.
🐡