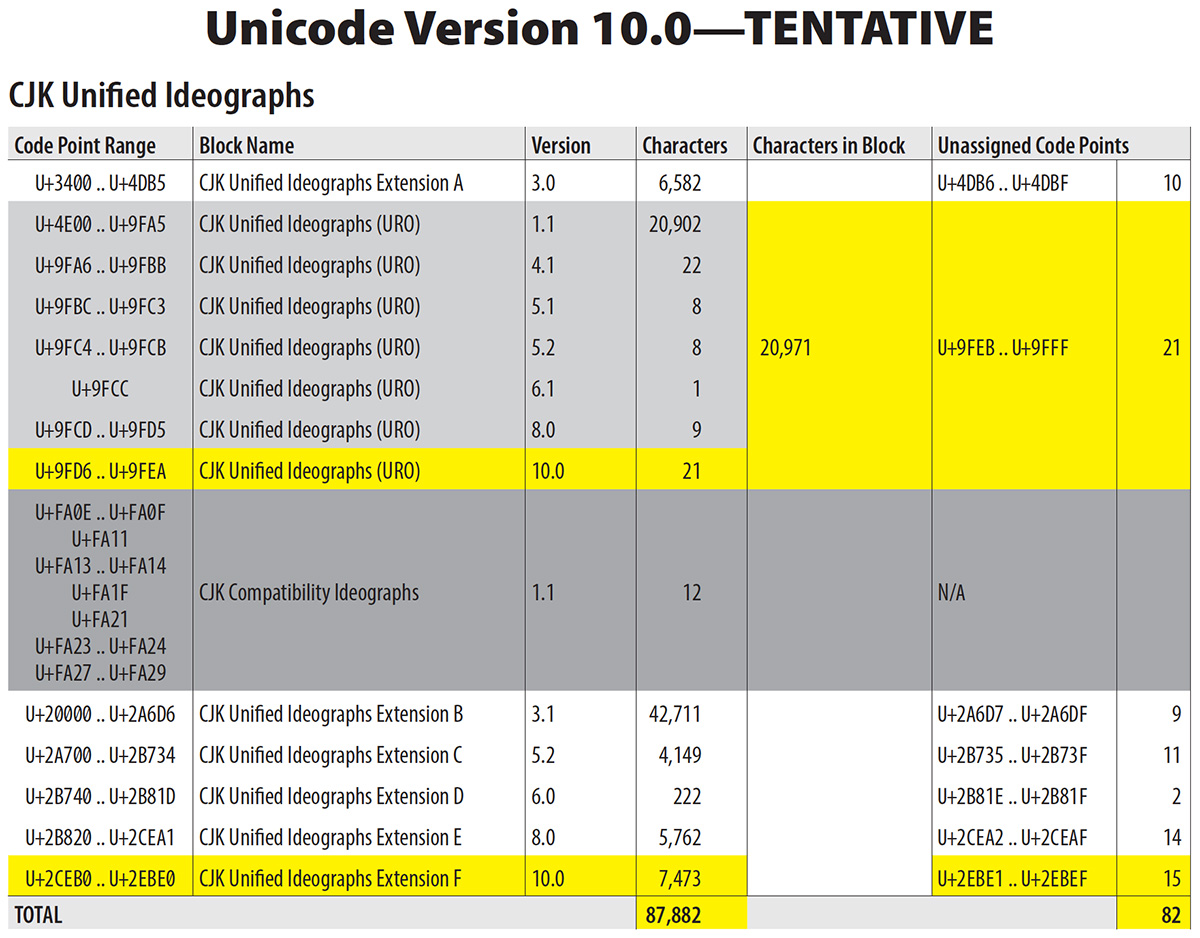
It is with great sadness that I write that Unicode Version 9.0, whose beta was authorized yesterday, on the last day of UTC #146, will include no additional CJK Unified Ideographs. The next opportunity for additional CJK Unified Ideographs is therefore Unicode Version 10.0, which is slated for a June 2017 release, and is expected to include 21 Urgently Needed Characters (UNCs) that are appended to the URO (Unified Repertoire & Ordering), along with Extension F (see IRG N2156 for the latest version) that currently includes 7,473 characters.
Interestingly, and as long as Extension F’s block remains stable, there are only 3,088 code points remaining in Plane 2 (SIP), specifically U+2EBF0 through U+2F7FF, along with 1,502 code points at the end of Plane 2, immediately following CJK Compatibility Ideographs Supplement, specifically U+2FA20 through U+2FFFD.
The image above is an excerpt of a PDF that shows what Unicode Version 10.0 is likely to include in terms of ideographs. If you click on the image, you will get the actual PDF. Of course, the yellow stuff is tentative and subject to change.
Updated on 2016-06-26 to reflect the additional UNC appended to the URO at U+9FEA, along with a net decrease of 12 characters in Extension F, reducing it to 7,473 characters.
🐡









