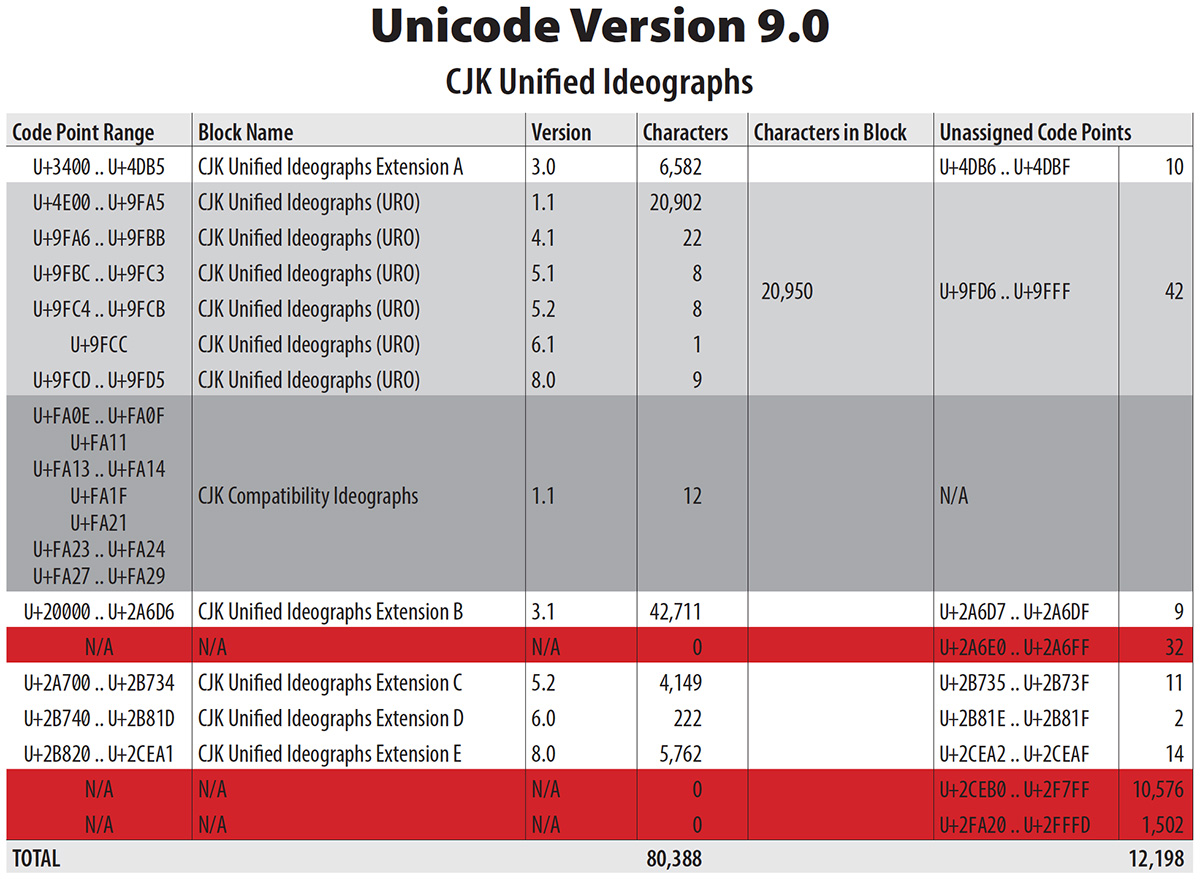
This will be a short, sweet, and to-the-point article. Sorry, no graphics nor photos.
When developing name-keyed fonts, glyph names matter. They matter a lot. When developing new fonts, the glyph names should either be explicitly listed in AGLFN (Adobe Glyph List For New Fonts) or derivable via the AGL Specification. Glyph names that adhere to AGLFN or the AGL Specification result in fonts with well-formed 'cmap' tables, which means that their glyphs will behave better in a broader range of environments. I cannot stress the importance of this.
CIDs (Character IDs), on the other hand, represent a completely different beast. If a font is genuinely CID-keyed, it means that there are absolutely no glyph names, regardless of whether the source font or fonts that were used to build the CID-keyed font were named-keyed. Once a font resource becomes CID-keyed, the original glyph names are literally jettisoned, and the only way in which to map Unicode values to glyphs is via the 'cmap' table, which is usually done using a UTF-32 CMap resource. In other words, when developing fonts that are intended to be deployed in a CID-keyed fashion, the source glyph names play absolutely no role in how such fonts are processed.
🐡