
As the title makes blatantly obvious, today we will cover a topic about China (中华人民共和国 zhōnghuá rénmín gònghéguó).
Continue reading…

As the title makes blatantly obvious, today we will cover a topic about China (中华人民共和国 zhōnghuá rénmín gònghéguó).
Continue reading…

For those who are not aware, there are twelve IDCs (Ideographic Description Characters) in Unicode, from U+2FF0 through U+2FFB, that are used in IDSes (Ideographic Description Sequences) which are intended to visually describe the structure of ideographs by enumerating their components and arrangement in a hierarchical fashion. Any Unicode character can serve as a IDS component, and the IDCs describe their arrangement. The IRG uses IDSes as a way to detect potentially duplicate characters in new submissions. All existing CJK Unified Ideographs have an IDS, and new submissions require an IDS.
This article describes a technique that uses IDSes combined with OpenType functionality to pseudo-encode glyphs that are unencoded or not yet encoded. If memory serves, it was Taichi KAWABATA (川幡太一) who originally suggested this technique.
Continue reading…
[For those who are interested in reading my own release notes for the Adobe-Japan1-6 UTF-32 CMap resource history, which includes the non-JIS2004 ones, I made them available here on January 20, 2016.]
I was recently asked, indirectly via Twitter, about changes and additions that were made to our JIS2004-savvy CMap resources, specifically UniJIS2004-UTF32-H and UniJISX02132004-UTF32-H. The former also includes UTF-8 (UniJIS2004-UTF8-H) and UTF-16 (UniJIS2004-UTF16-H) versions that are kept in sync with the master UTF-32 version by being automagically generated by the CMap resource compiler (and decompiler), cmap-tool.pl, which I developed years ago.
Of course, all of these CMap resources also have vertical versions that use a “V” at the end of their names in lieu of the “H,” but in the context of OpenType font development, the vertical CMap resources are virtually unused and worthless because it is considered much better practice to explicitly define a ‘vert‘ GSUB feature for handling vertical substitution. In the absence of an explicit definition, the AFDKO makeotf tool will synthesize a ‘vert’ GSUB feature by using the corresponding vertical CMap resources.
With all that being said, what follows in this article is a complete history of these two CMap resources, which also assign dates, and sometimes notes, to each version.
Continue reading…
I spent a couple of days curling up with GB 18030 (both versions: 2000 and 2005), which is PRC’s latest and greatest national character set standard, and came across an oddity that my gut tells me is a design flaw. At the very least, it is an issue about which font developers need to be aware.
What I found were eight instances of CJK Unified Ideographs with a left-side Radical #130 that uses the Traditional Chinese or Taiwan-style form, instead of the expected Simplified Chinese or PRC-style form that looks the same as Radical #74. Screen captures from the latest Unicode Code Charts, whose glyphs agree with both versions of GB 18030, are shown below:

As the IVD Registrar, I am very pleased to announce PRI 259 (Public Review Issue #259), which is the combined registration of the new Moji_Joho IVD Collection and sequences for that IVD collection. According to procedures set forth in UTS #37 (Unicode Technical Standard #37, Unicode Ideographic Variation Database), the 90-day public review, which commences today, allows interested parties to submit comments, suggestions, and errors to the registrant via Unicode’s reporting form.
Continue reading…
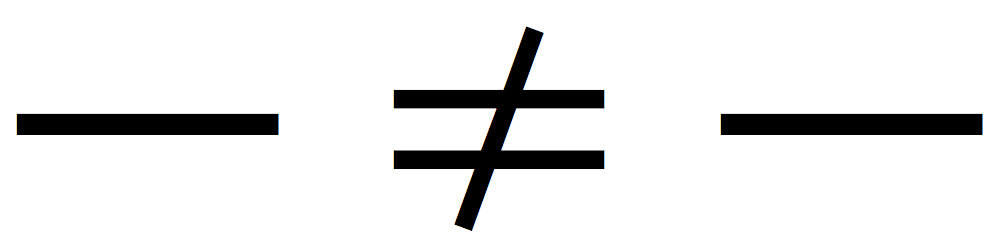
Not all PDF authoring applications are the same, in terms of the extent to which they preserve the text content of the original document. Of course, this is not necessarily the fault of the PDF authoring application, but rather it is due to a disconnect between the PDF authoring process and access to the text content of the original document.
The best example for demonstrating this is to create a document that includes the two kanji 一 (U+4E00) and ⼀ (U+2F00). The reason why these two characters represent a good example is because in mainstream Japanese fonts, mainly those that are based on the Adobe-Japan1-x ROS, both map to the same glyph, specifically CID+1200.
If you download and unpack the 4E00vs2F00.zip file, you will find two PDF files, an Adobe InDesign file, and an MS Word file. If you open the original documents and search for 一 (U+4E00), you will find only a single instance, which is the one that is marked by the Unicode scalar value. However, if you open the respective PDF files, you will notice a difference. The one that is based on the MS Word file now includes two instances of 一 (U+4E00), and ⼀ (U+2F00) is no longer included in its content. You can search a PDF file by Unicode scalar value by using the “\uXXXX” notation, such as \u4E00 for U+4E00 (一). (Note: Depending on the version of MS Word that is being used, the PDF file may instead include two instances of ⼀ (U+2F00). I am using Microsoft Word for Mac 2011 Version 14.3.8.)
Adobe InDesign has a built-in PDF library that has direct access to the text content, and is thus able to inject it into the text layer of the PDF file that it produces. MS Word uses a different pathway for producing a PDF file, one that does not have access to the text content of the original document.
For those who have been interested in ISO/IEC 14496-28:2012 (Composite Font Representation), which standardizes an XML format for defining font objects (aka CFR objects) that can reference more than one font resource and thus break the 64K glyph barrier, I am pleased to let this blog’s readership know that it is now among ISO’s Freely Available Standards. I am particularly pleased about this news, mainly because some developers have indicated that purchasing the standard effectively served as a barrier to supporting it. Well, the barrier has been removed!
Note that this change makes a whole lot of sense, because two ISO standards that are closely tied to CFR, ISO/IEC 10646 (Universal Coded Character Set, aka Unicode) and IEO/IEC 14496-22 (Open Font Format), are already among these freely available standards.
Also note that there is no direct download URL for this or other freely available ISO standards, because one must first agree to the no-cost licensing terms by clicking a button.
Some people naïvely think that ISO/IEC 10646 and Unicode, which are joined at the hip, make the development of national standards an obsolete practice. As my IRG41 contribution, IRG N1964 (Continued National Standards Development & Horizontal Extensions), makes clear, nothing is further from the truth, especially when it involves CJK Unified Ideographs.
The content of this paper had been brewing in my head since IRG38, and only recently has congealed into a concise one-page paper that should be daunting to no one. If you are interested in such issues, please read the paper and provide feedback.
While the finishing touches are being put on Unicode Version 6.3, which will include the 1,002 Standardized Variants that I already mentioned, everything appears to be on track for Unicode Version 7.0, which will be in sync with ISO/IEC 10646:2014 (4th Edition).
Extension E, which adds 5,762 new CJK Unified Ideographs, is on track to be included in Version 7.0. This will bring the total number of CJK Unified Ideographs to a staggering 80,379 characters. I spent part of this morning preparing an updated version of my CJK Unified/Compatibility Ideographs table that provides a glimpse at Unicode Version 7.0.
(Note that neither Unicode Version 7.0 nor ISO/IEC 10646:2014 have been released or published, meaning that implementers should keep this caveat in mind, hence the use of “glimpse” in the title of this article.)
As I described in Part 1, Part 2, and Part 3 of this series, Standardized Variants offer a Normalization-proof representation for the 1,002 CJK Compatibility Ideographs, which are encoded in the BMP, and at the end of Plane 2. These 1,002 Standardized Variants have been approved, and will be included in Unicode Version 6.3. They will, of course, also be included in IS0/IEC 10646.
In an effort to provide to font developers advance support for the Standardized Variants that correspond to glyphs in Adobe’s public ROSes, the next version of AFDKO will include a new version of the Adobe-Japan1_sequences.txt file that appends entries that correspond to 89 of these Standardized Variants, along with Adobe-CNS1_sequences.txt and Adobe-Korea1_sequences.txt files that specify 14 and 270 entries, respectively, that correspond to these Standardized Variants. If you click on the file names, you can download the files and use them immediately. These are used with the AFDKO makeotf tool, and specified as the argument of the “-ci” command-line option.
Baby steps…