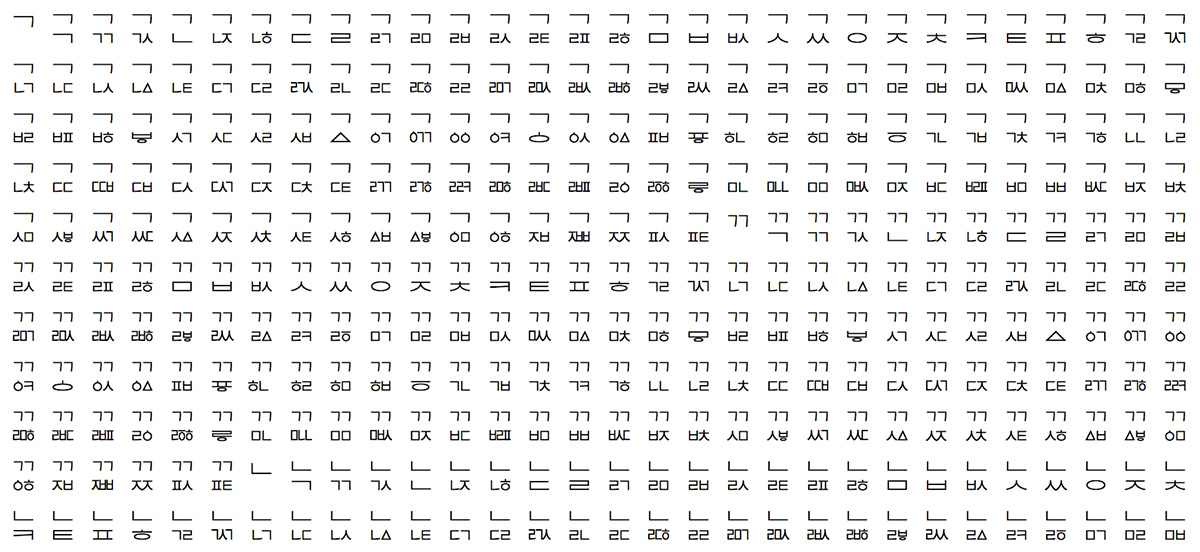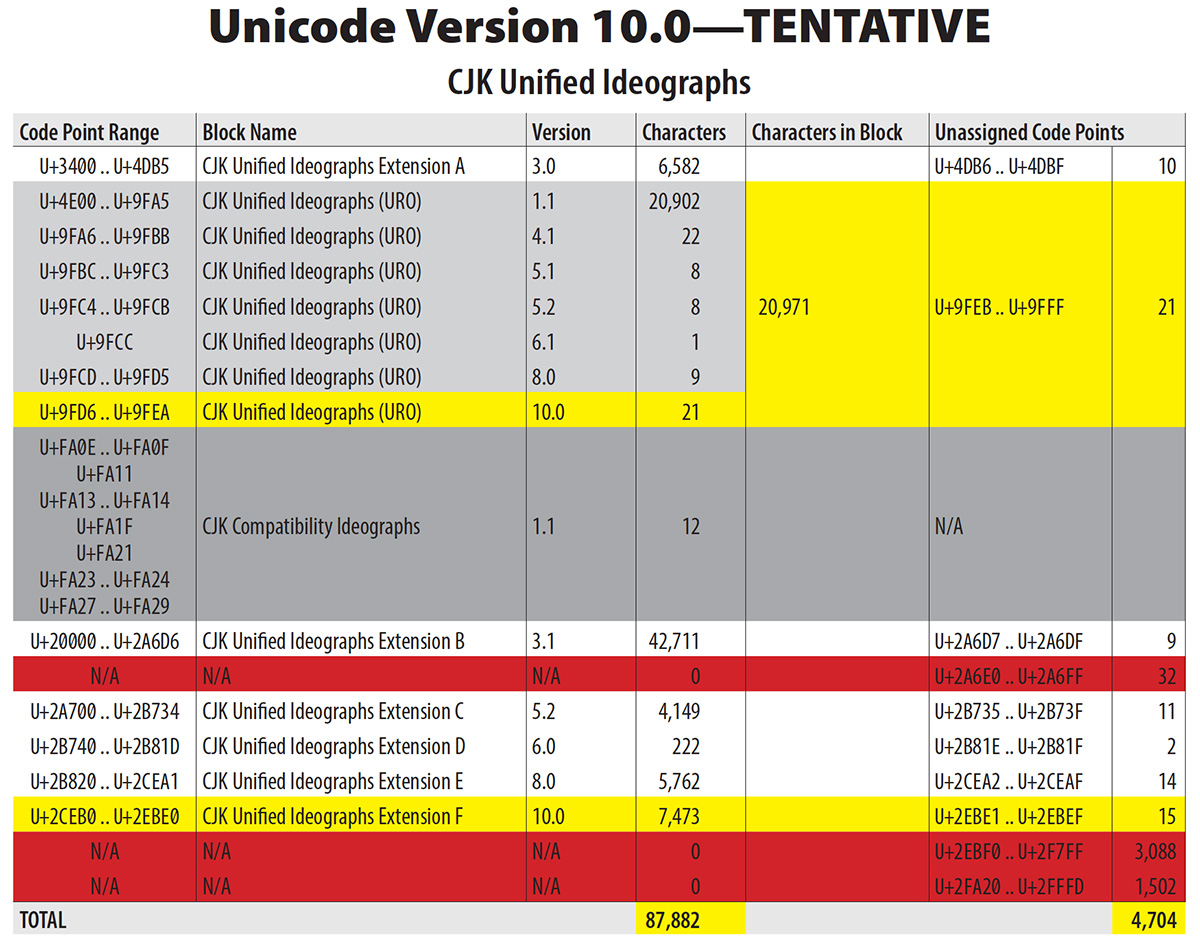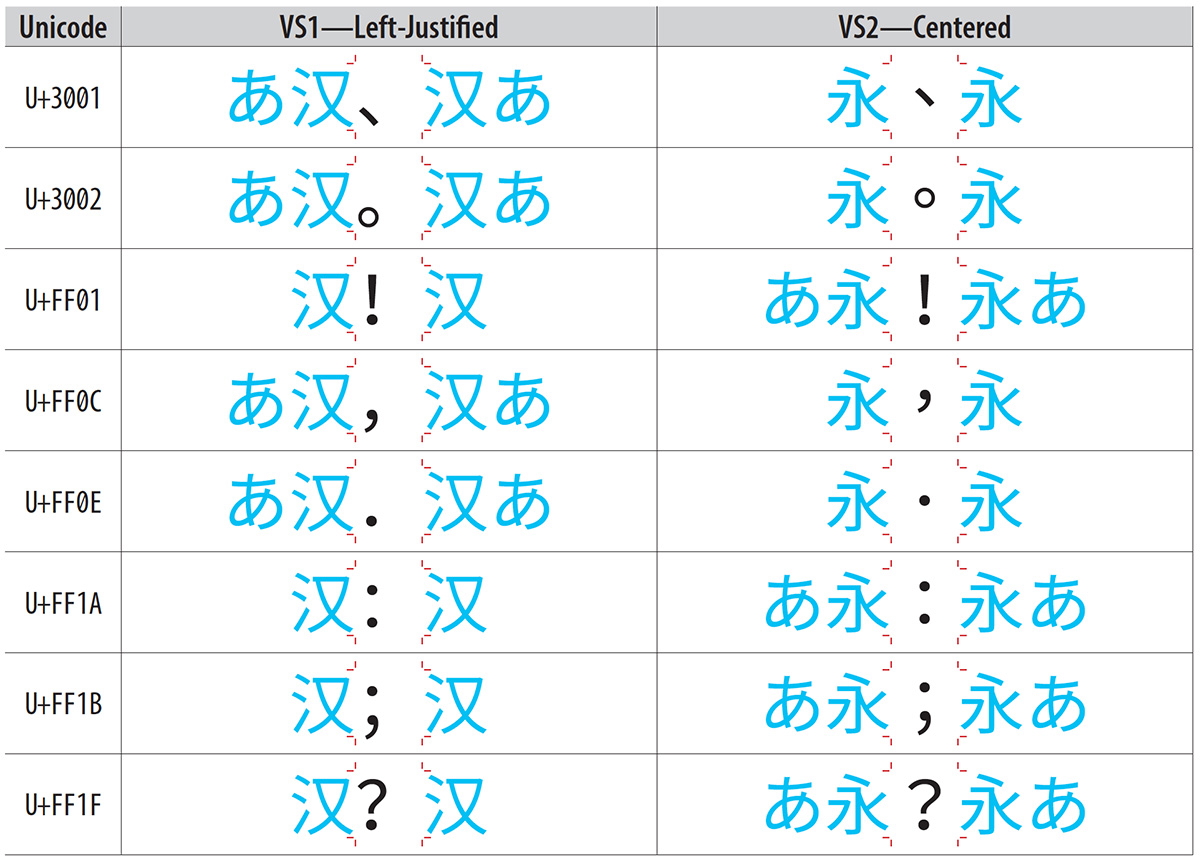
This article is largely a test, but also serves to start the process of resurrecting L2/14-006 (Proposal to add standardized variation sequences for nine characters) for discussion at UTC #151 in early May.
Liang Hai (梁海) brought up this document for discussion at UTC #150 last week, and while I had an opportunity to have it accepted by the UTC, to be included in Unicode Version 10.0 (June, 2017), I decided that it was prudent to instead prepare a revised proposal that is more complete, mainly because L2/14-006 was submitted and discussed prior to the first release of the Adobe-branded Source Han Sans and Google-branded Noto Sans CJK Pan-CJK typeface families. This functionality was implemented in those typeface families via the 'locl' GSUB feature, which requires the text to be language-tagged. In other words, I learned a lot since L2/14-006 was discussed, and prefer to submit a more complete proposal, even if it means waiting for Unicode Version 11.0 (June, 2018).
Continue reading…