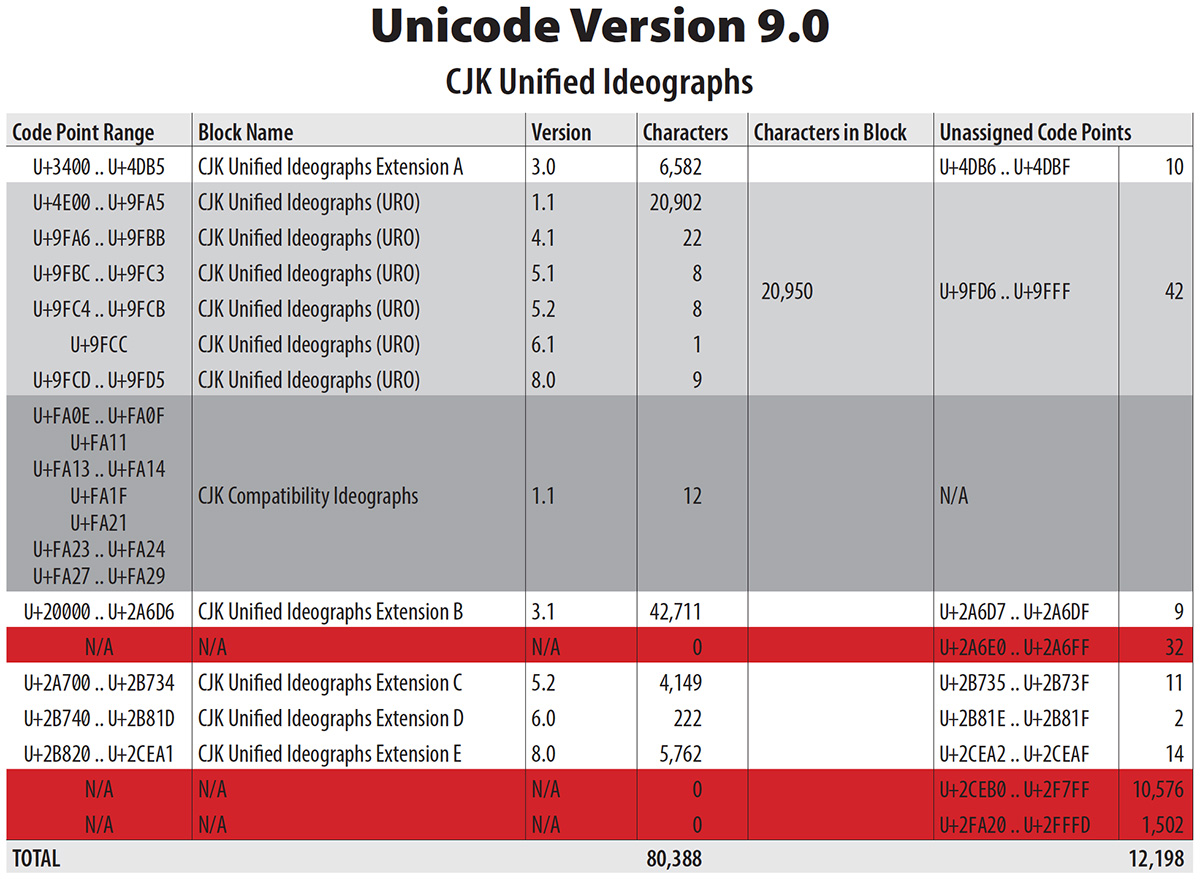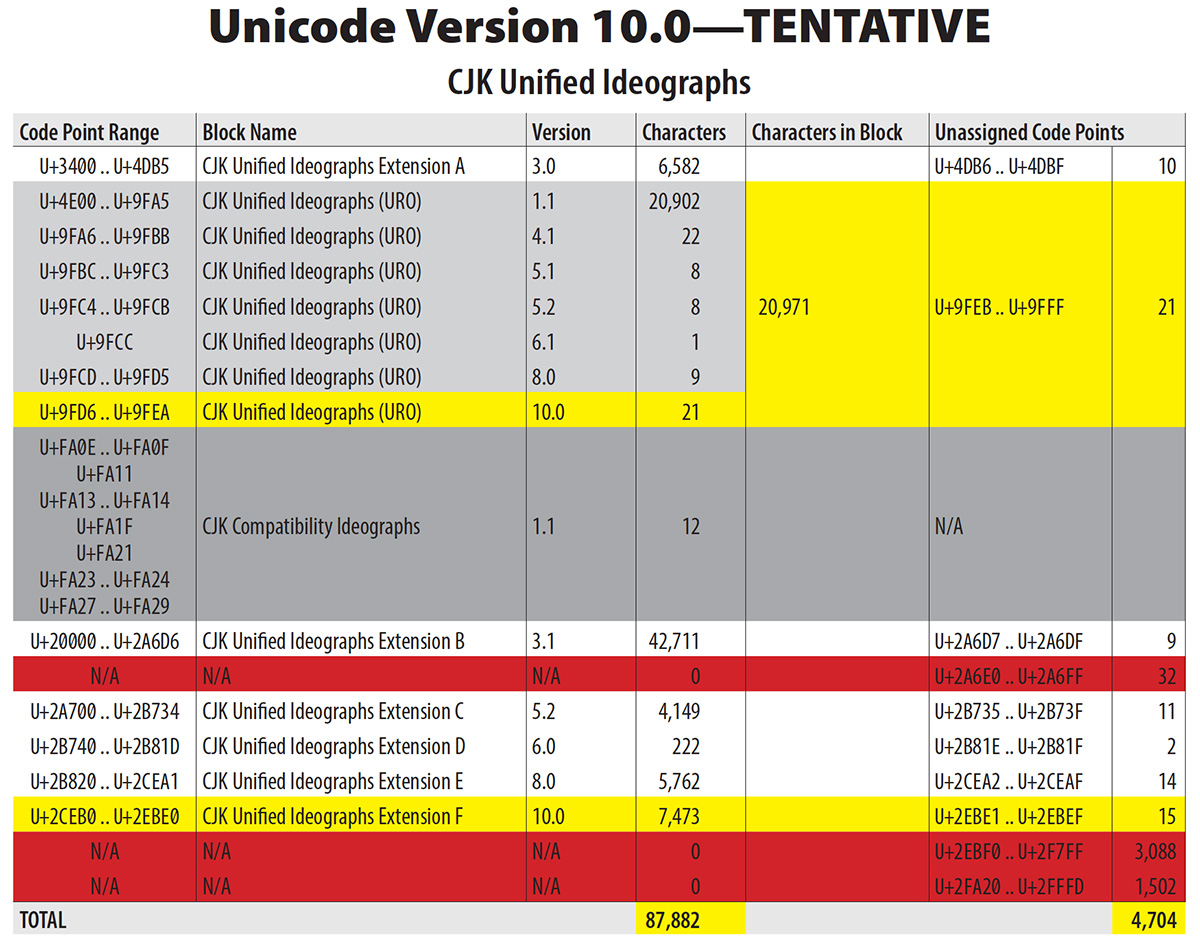
UTC #148 took place in Redmond, Washington last week, hosted by our friends at Microsoft. It was a four-day working meeting, and many important Unicode-related issues and proposals were discussed. A total of 7,888 new characters were formally accepted into the standard during this meeting. Among them were the 7,473 CJK Unified Ideographs of Extension F, along with the lone CJK Unified Ideograph U+9FEA that is appended to the URO (Unified Repertoire & Ordering) and is the result of the disunification of 㸂 U+3E02, which were accepted on 2016-08-04 for inclusion into Unicode Version 10.0. Version 10.0 is slated for a June 2017 release. This means that my table above is now less tentative (clicking on the image will reveal the entire PDF file that includes details about the unchanged CJK Compatibility Ideographs).
Other CJK Unified Ideographs that are slated to be included in Unicode Version 10.0 are the 20 characters, U+9FD6 through U+9FE9, which were accepted on 2014-10-28 (UTC #141).
This will bring the total number of CJK Unified Ideographs to 87,882, and as the table at the top of this article suggests, there is not much room left in Plane 2, and Extension G is just around the corner.
😱
For those who are curious about the 414 other new characters that were accepted during UTC #148, please click here, here, here, here, here, here, and here.
🐡