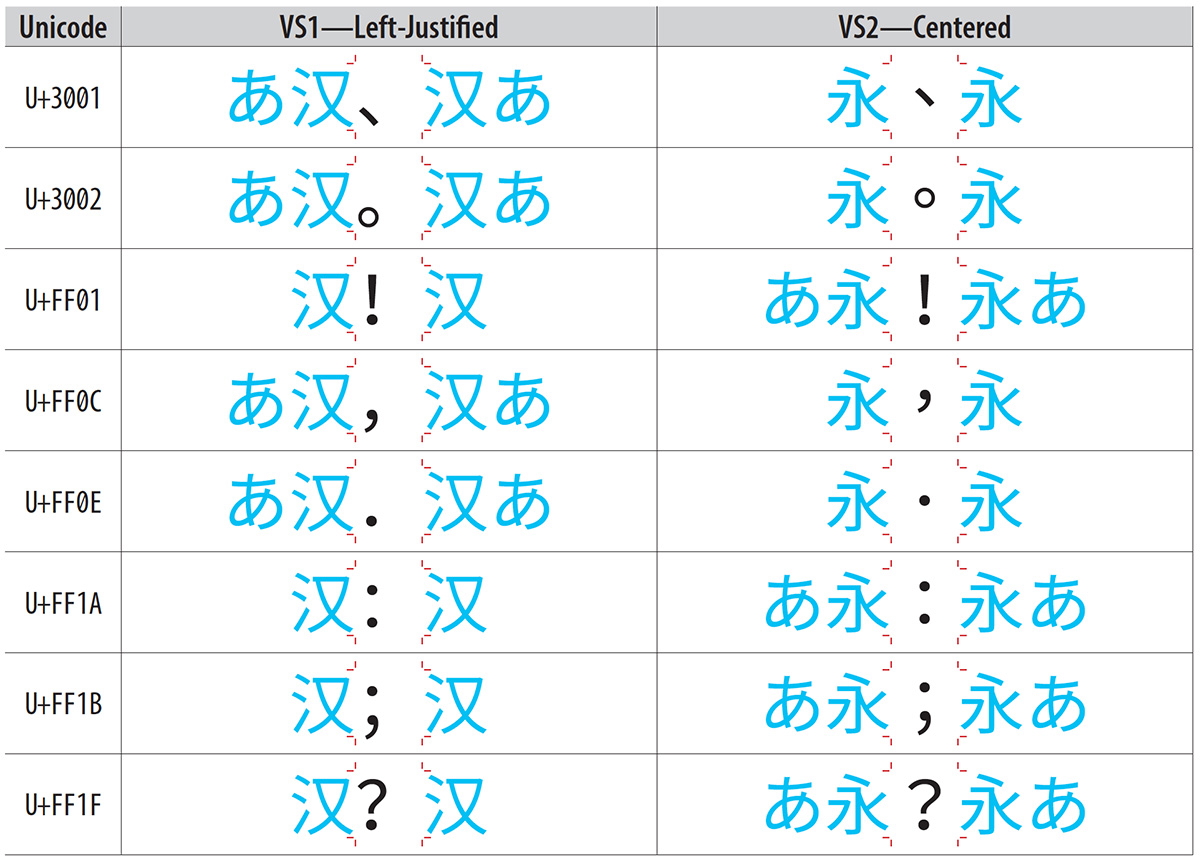
The IVD (Ideographic Variation Database) is all about ideograph variants. Up until earlier this year, its scope was limited to CJK Unified Ideographs, per UTS #37 (Unicode Ideographic Variation Database). Its scope now includes characters with the Ideographic property that are not canonically nor compatibly decomposable, which still excludes CJK Compatibility Ideographs.
In an ideal world, a particular glyph—whether it’s considered the standard (aka encoded) form or an unencoded variant of the standard form—would be associated with a single registered IVS (Ideographic Variation Sequence) within an IVD collection. However, we do not live in a perfect world, and several real-world conditions can lead to duplicate sequence identifiers within an IVD collection.
Continue reading…