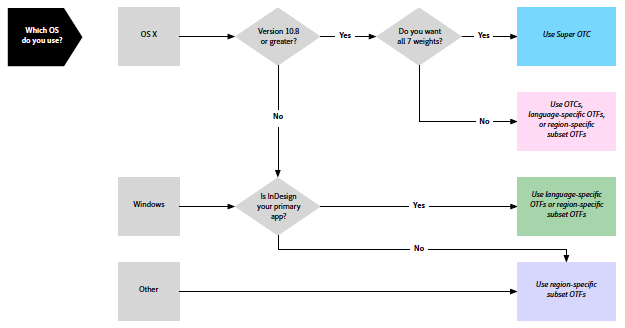
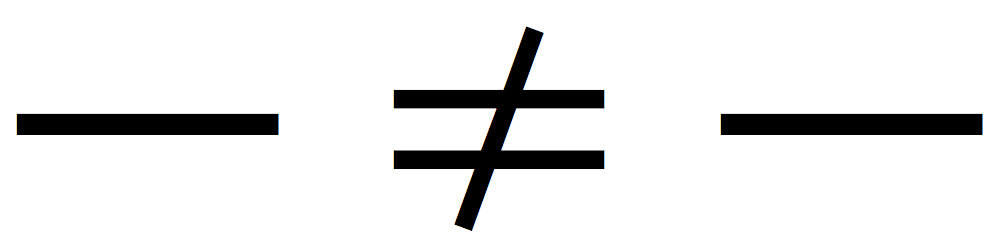Not all PDF authoring applications are the same, in terms of the extent to which they preserve the text content of the original document. Of course, this is not necessarily the fault of the PDF authoring application, but rather it is due to a disconnect between the PDF authoring process and access to the text content of the original document.
The best example for demonstrating this is to create a document that includes the two kanji 一 (U+4E00) and ⼀ (U+2F00). The reason why these two characters represent a good example is because in mainstream Japanese fonts, mainly those that are based on the Adobe-Japan1-x ROS, both map to the same glyph, specifically CID+1200.
If you download and unpack the 4E00vs2F00.zip file, you will find two PDF files, an Adobe InDesign file, and an MS Word file. If you open the original documents and search for 一 (U+4E00), you will find only a single instance, which is the one that is marked by the Unicode scalar value. However, if you open the respective PDF files, you will notice a difference. The one that is based on the MS Word file now includes two instances of 一 (U+4E00), and ⼀ (U+2F00) is no longer included in its content. You can search a PDF file by Unicode scalar value by using the “\uXXXX” notation, such as \u4E00 for U+4E00 (一). (Note: Depending on the version of MS Word that is being used, the PDF file may instead include two instances of ⼀ (U+2F00). I am using Microsoft Word for Mac 2011 Version 14.3.8.)
Adobe InDesign has a built-in PDF library that has direct access to the text content, and is thus able to inject it into the text layer of the PDF file that it produces. MS Word uses a different pathway for producing a PDF file, one that does not have access to the text content of the original document.