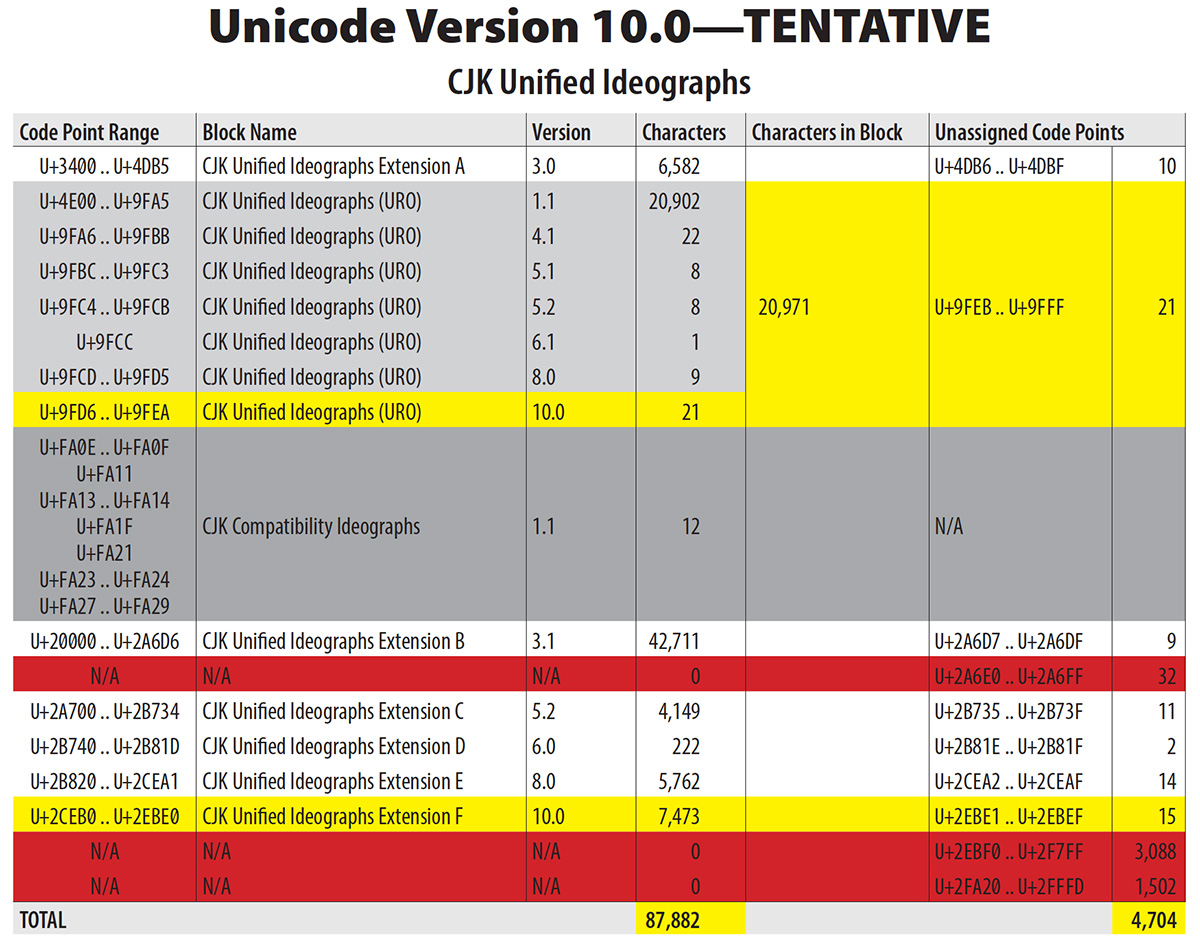
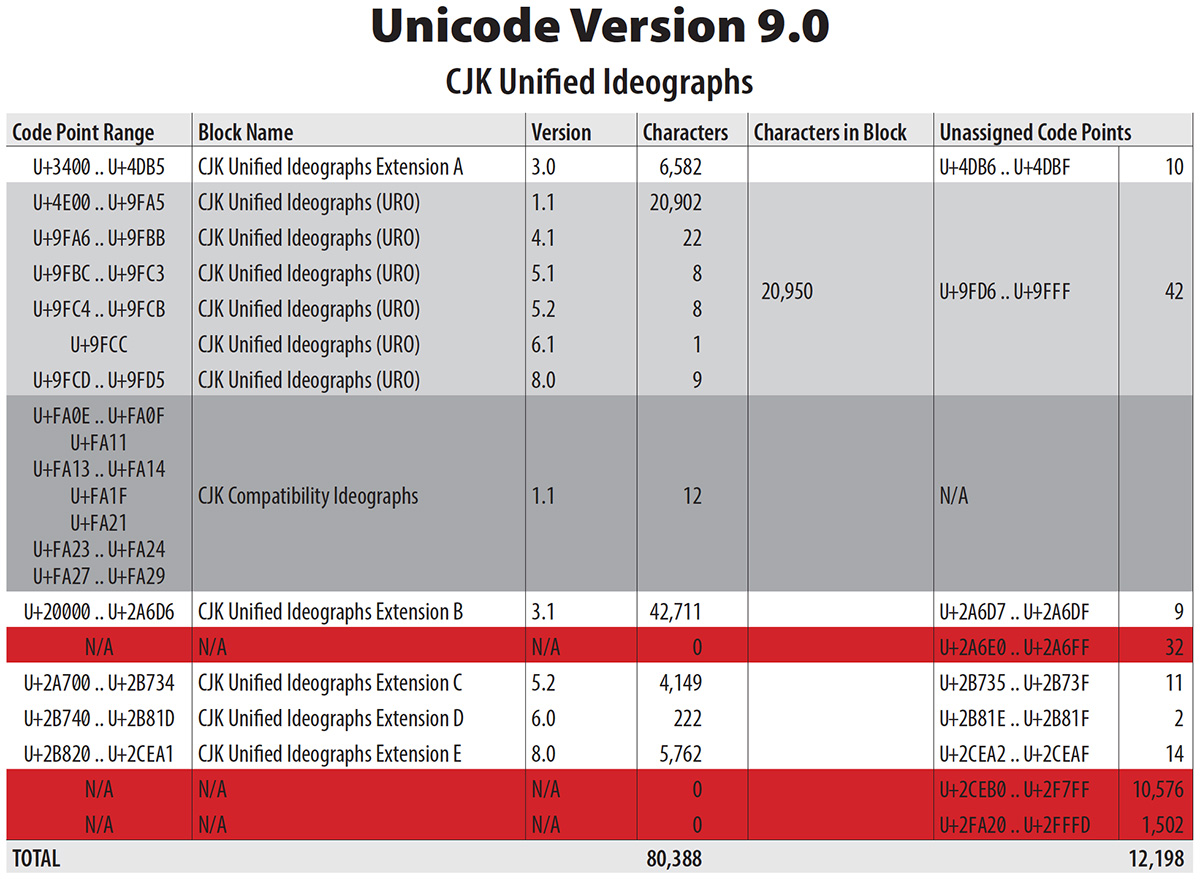
As a follow on to our seven-year-old May of 2009 article of the same name, several things have happened with the Adobe Clean family that have yet to be reported, and which have CJK implications. Hence the reason for spending my Sunday morning writing this article.
In the following year, 2010, I developed and deployed a Japanese version of Adobe Clean named Ryo Clean PlusN (りょう Clean PlusN in Japanese), and then in 2015, I developed and deployed a Pan-CJK version named Adobe Clean Han (Adobe Clean 黑体 in Simplified Chinese, Adobe Clean 黑體 in Traditional Chinese, Adobe Clean 角ゴシック in Japanese, and Adobe Clean 고딕 in Korean). These typeface families are Adobe corporate fonts that are meant to be used for product literature, for serving to Adobe websites, and for use by Adobe apps. They are not meant to be used by our customers, but I suspect that the readership of this blog may be interested in some of the development details. If this interests you, please continue reading.
Continue reading…